Customize shard count
Shards affect a pipeline's throughput. Increasing the shard count for a pipeline increases the maximum throughput. By default, each pipeline is configured with two shards.
To set the shard count, use the --shard-count flag while creating or updating a pipeline:
$ npx wrangler pipelines update [PIPELINE-NAME] --shard-count 10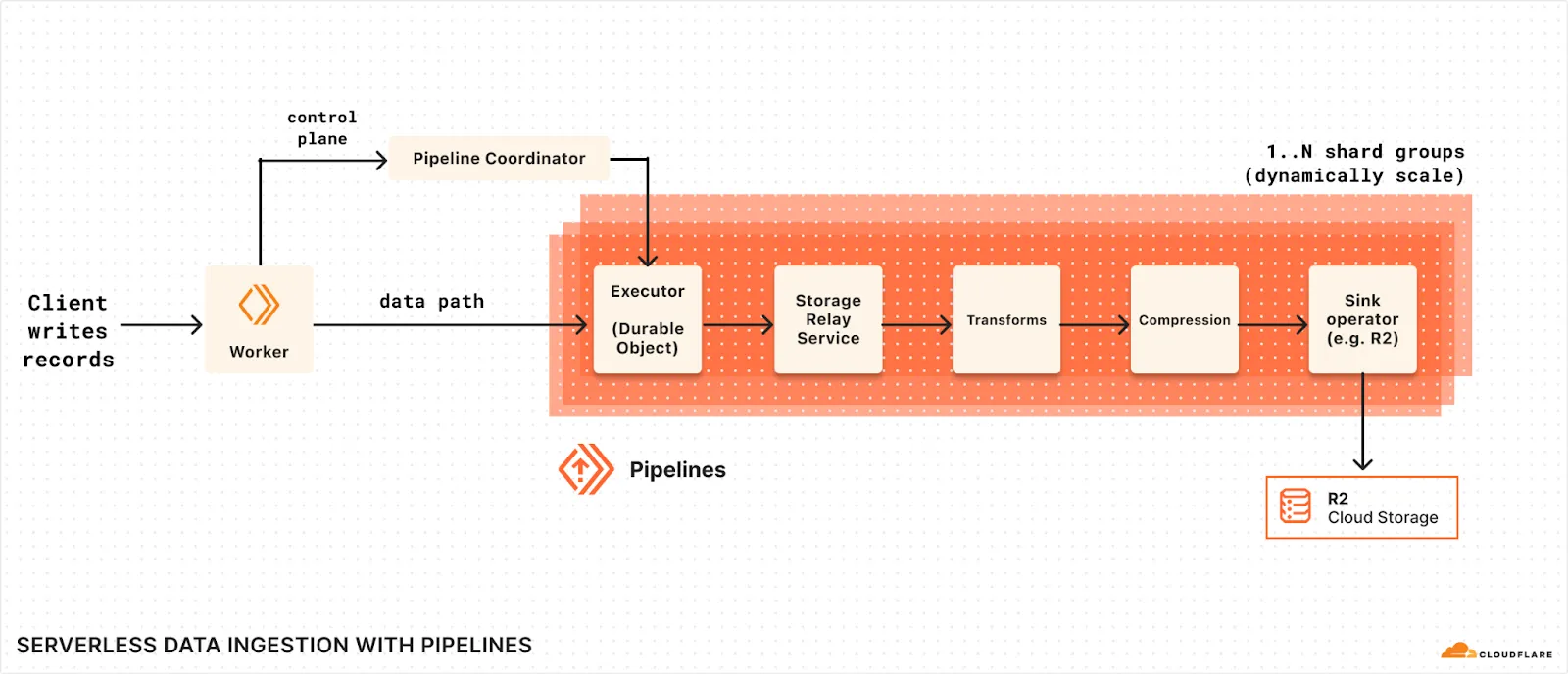
Each pipeline is composed of stateless, independent shards. These shards are spun up when a pipeline is created. Each shard is composed of layers of Durable Objects. The Durable Objects buffer data, replicate for durability, handle compression, and delivery to R2.
When a record is sent to a pipeline:
- The Pipelines Worker receives the record
- The record is routed to to one of the shards
- The record is handled by a set of Durable Objects, which commmit the record to storage, and replicate for durability.
- Records accumulate, until the batch definitions are met.
- The batch is written to an output file, and optionally compressed.
- The output file is delivered to the configured R2 bucket
Increasing the number of shards will increase the maximum throughput of a pipeline, as well as the number of output files created.
Your workload might require making 5,0000 requests per second to a pipeline. If you create a pipeline with a single shard, all 5,000 requests will be routed to the same shard. If your pipeline has been configured with a maximum batch duration of 1 second, every second, all 5,000 requests will be batched, and a single file will be delivered.
Increasing the shard count to 2 will double the number of output files. The 5,000 requests will be split into 2,500 requests to each shard. Every second, each shard will create a batch of data, and deliver to R2.
Increasing the shard count also increases the number of output files that your pipeline generates. This in turn increases the cost of writing data to R2, as each file written to R2 counts as a single class A operation. Additionally, smaller files are slower, and more expensive, to query. Rather than setting the maximum, choose a shard count based on your workload needs.
Choose a shard count based on these factors:
- How many requests per second you will make to your pipeline
- How much data per second you will send to your pipeline
Each shard is capable of handling approximately 7,000 requests per second, or ingesting 7 MB / s of data. Either factor might act as the bottleneck, so choose the shard count based on the higher number.
For example, if you estimate that you will ingest 70 MB / s, making 70,000 requests per second, setup a pipeline with 10 shards. However, if you estimate that you will ingest 70 MB / s while making 100,000 requests per second, setup a pipeline with 15 shards.
| Setting | Default | Minimum | Maximum |
|---|---|---|---|
Shards per pipeline shard-count | 2 | 1 | 15 |